

 Your new post is loading...
Your new post is loading...
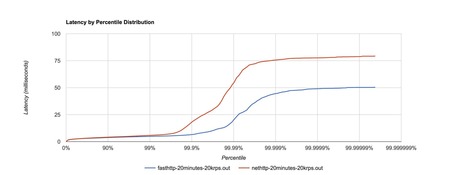

Recently our team has been tasked to write a very fast cache service. The goal was pretty clear but possible to achieve in many ways. Finally we decided to try something new and implement the service in Go. We have described how we did it and what values come from that.